Thursday, December 4, 2025
Three C's: Connection


Connection
Sylow's mission to build useful AI software hinges on what we call the three C's:
- Connection
- Collaboration
- Context
In these weekly deep-dives, I'll be picking apart each of these and giving Sylow's perspective on why we believe it's a justified component of our mission, how we think about building it, and some insight into our overall approach.
Connection is a core tenet for a very simple reason
What use is having a technology trained on all the public information in the world if it can't make sense of your private information? The output of that equation is the current state of the tech: extremely helpful, not particularly useful.
To get use out of this technology, it must connect to everything—your software, your databases, anywhere and everywhere your information lives.
Decisions are rarely made on a single data source. Every step in a decision-making process is multivariate, and the more information you have to work with, the more informed a decision you can make.
Now, how do we represent that for an AI?
There's a relevant branch of mathematics called Information Theory. What's important for you to know is that information is measured by how much it reduces uncertainty. A single data source gives you one view. Two independent sources give you more than double the information, and three sources compound that further. So on, and so on.
So, when I have a giant corpus of public information (like what ChatGPT is trained on) and tell it to make a guess on top of a small amount of private information, the results are invariably lackluster. When you increase the amount of private information available at query time, the model can much better leverage the giant amount of data it was trained on to create a great answer.

This scales exponentially, not linearly. So even just a few more data sources can reduce model uncertainty by a significant margin.
Connection is hard
So that sounds great and all, but actually getting that large amount of private information into the query is not easy, primarily because the software used in many business settings is just not optimized for AI use cases.
Most companies we've spoken to have a similar pattern: Salesforce here, Slack there, Google Drive somewhere, an ancient ERP system, maybe a data warehouse that a few people know how to query.
This setup forces employees into a similar rhythm of copy-pasting, downloading CSVs, uploading to ChatGPT, hoping for the best, and emailing it up the chain.
The problem isn't just that these systems are disconnected, it's that they were never designed to be machine-readable in the first place.
Most enterprise software was built for humans clicking through interfaces, not for AI agents making programmatic queries.
The access problem.
Authentication models assume a human is logging in, not an agent operating on behalf of multiple users with different permission levels. (If you are interested in this, by the way, check out our talk with Lightning AI where we go over agentic security)
And even when you get data out, it's rarely in a format that's immediately useful—Salesforce's nested JSON structures look nothing like Slack's message threading model, which looks nothing like your ERP's relational tables.
Then there's the permission problem. Most AI integrations either use a service account with god-mode access (terrible for security) or prompt users for credentials every time (terrible for usability).
Neither approach scales, and neither respects the nuanced access controls your company already has in place. Your sales rep shouldn't be able to ask an AI about engineering roadmaps just because the AI technically has access to your project management tool.
What connection means to us is that the model can pull from all of these simultaneously, respecting permissions, handling rate limits intelligently, normalizing data formats on the fly, and doing it fast enough that you're not waiting 30 seconds for a response. Not connecting to Salesforce, asking a question, disconnecting, then connecting to Slack for another question.
Approaching an experience where one can ask, "How's the ABC Corp deal looking?" and having the model pull from last week's Slack thread with their CTO, the contract sitting in DocuSign, the support tickets they filed last month, that spreadsheet your sales engineer made, and the meeting notes from the kickoff call, All at once, synthesized into a single coherent answer.
How workspaces works.
This is what we've spent the last several months building at Sylow. Workspaces handles the unglamorous infrastructure work. Building adapters for legacy systems that were never meant to be machine-readable, implementing permission inheritance that respects your existing access controls, managing rate limits and caching strategies that keep responses fast, and normalizing data across wildly different schemas.
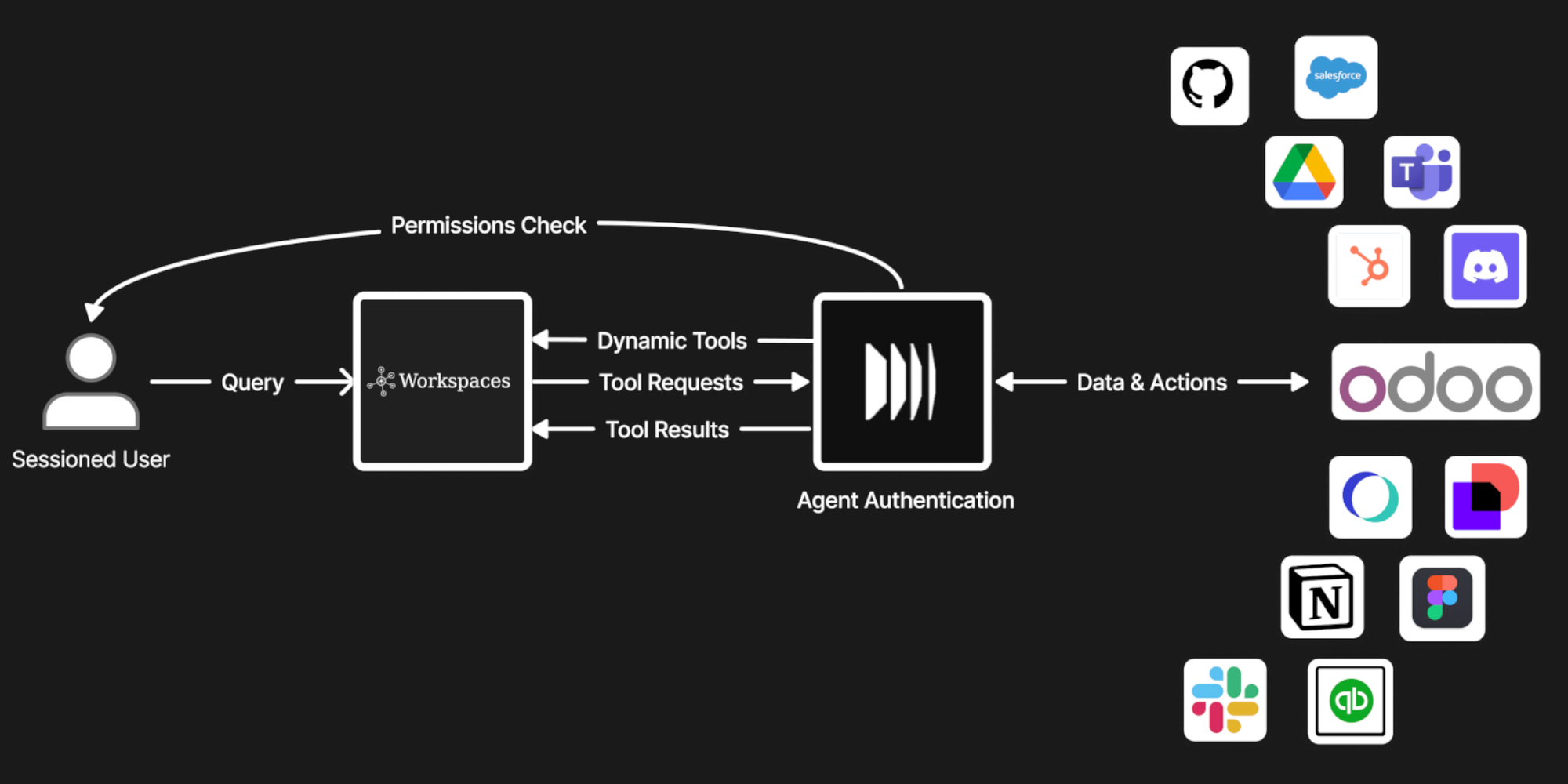
The engineering challenge isn't just connecting to these systems; it's making those connections reliable, secure, and fast enough to feel instantaneous. We've built Workspaces so you don't need a data engineering team to set it up or a six-month implementation timeline to see value. Connect your apps, define what the workspace is for, and start asking questions.
That's the foundation. But here's the thing: even with perfect access to all your systems, the model is still just providing information. Real decisions happen in conversations: with your team, with stakeholders, with the people who have context the systems don't capture. Connection solves the data problem, but it doesn't solve the decision-making problem.
Next up: Collaboration
Connection gets you the data, but data alone doesn't make decisions. People do. Your teams do.
Next week, I'll talk about why we built Workspaces as a collaborative tool first and an AI tool second, because the model isn't meant to replace your team. It's meant to be part of it.
Thank you very much for reading, and sign up for the Workspaces beta below!
Ethan Henley